(2019年文章)
深度学习现在这么火热,大部分人都会有‘那么它与机器学习有什么关系?’这样的疑问,网上比较它们的文章也比较多,如果有机器学习相关经验,或者做过类似数据分析、挖掘之类的人看完那些文章可能很容易理解,无非就是一个强调‘端到端’全自动处理,一个在特征工程上需要耗费大量时间和精力(半自动处理);一个算法更复杂、需要更多的数据和算力,能解决更复杂的问题,一个算法可解释性强,在少量数据集上就可以到达一定的效果。但是如果对于一个之前并没有多少机器学习相关背景、半路出道直接杀入深度学习领域的初学者来讲,可能那些文章太过理论。本篇文章尝试使用传统机器学习和深度学习两种不同的方法去解决同一个问题,告诉你它们之间有哪些联系。
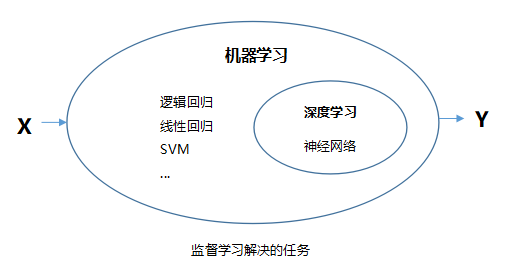
首先需要指出的是,主流定义上机器学习包含深度学习,后者是前者的一个分支。机器学习中有不同的算法,比如线性回归、逻辑回归、SVM、决策树、神经网络等等。由于使用神经网络算法的机器学习比较特殊,所以单独命名这类机器学习为‘深度学习’(为什么叫深度,后面详细说)。因此,比较两者联系更准确的表述应该是:传统机器学习和深度学习的关系(这里的传统机器学习不包含使用神经网络算法这一类)。另外需要明确的是,在处理监督学习问题中,机器学习不管采用什么算法,解决问题最终方式都是一致的:即找出X->Y的映射关系。比如你的模型用线性回归或者神经网络算法,最后都是要从训练素材中找输入和输出之间的映射关系。
现在就以一个图片二分类的任务为例,分别使用基于神经网络的深度学习和基于逻辑回归算法的传统机器学习两种方式解决,让我们看看它们在解决问题上的区别和联系。这个例子并没有源代码,我希望用图片来说明问题。
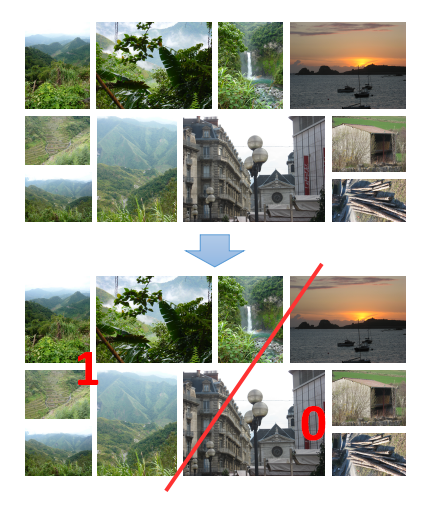
如上图,有一堆风景照片,我们需要训练一个模型来判断给定图片是否属于绿植风景照,这是一个二分类问题,绿植风景照属于第一类,其他属于第二类。输入一张图片,模型输出图片类型。现在我们分别用深度学习和传统机器学习的方法尝试去解决该问题。这里需要明确的是,对于图片分类而言(或其他大部分跟CV有关的应用),不管是用深度学习还是传统机器学习,都是需要先得到每张图片的特征表示(特征向量),特征向量是一张图片的信息压缩表示,如果不太了解何为图像特征,可以参考这篇博客:https://www.cnblogs.com/xiaozhi_5638/p/11512260.html,里面介绍了图像特征的作用和传统图像特征提取方式。
深度学习
对于深度学习而言,这个图片二分类问题太简单了,网上深度学习入门教程一大堆,比如猫狗识别跟这个差不多。在神经网络开始,我们使用几个(卷积层-池化层)的block块,提取图片的高维特征,然后再使用几个连续的(卷积层)块提取低维特征。在神经网络末尾,我们再加一个MLP全连接网络做为特征分类器,分类器最后包含一个输出节点(使用Sigmoid激活函数),代表预测为绿植风景照的概率,概率越接近1代表它为绿植风景照的可信度越高。这个网络结构可以参考2012年将深度学习带入大众视野的AlexNet网络。

如上图,图片直接输入到模型,神经网络负责特征提取,并且对特征进行分类,最后输出概率值。我们可以看到,对于深度学习方式而言,我们在预测一张图的分类时,只需要将图片传给神经网络(可能需要事先调整一下图片尺寸),然后在神经网络的输出端就可以直接得到它所属分类的概率值。这种全自动、无需人工干预的工作方式我们称之为“端到端”(End-To-End)的方式。我们可以将上述网络结构(like-alexnet)使用python代码构建出来,然后图像化显示:
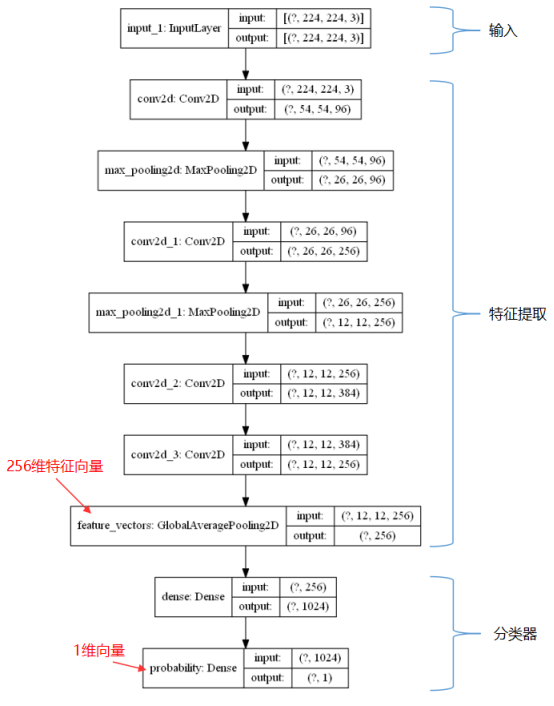
如上图所示,神经网络在处理该图片分类任务时,从开始到结束一条龙服务。神经网络接收一张214*214大小的3通道彩图,矩阵形状为(214,214,3)。然后经过特征提取,得到一个256维的特征向量。最后进行特征分类,直接输出它的概率。注意上图为了简化结构,神经网络仅仅包含必要的卷积层、池化层以及全连接层,实际情况可能还需要归一化、Dropout等结构。(忽略上图Input和Output中的?号,它表示batch-size,即穿过神经网络的图片数量)需要说明的是,随着问题的复杂性加大(比如图片特征不明显,分类数量增多,数据复杂等等),我们还可以灵活调整上图中神经网络的结构,图中是最简单的直线型网络结构(Sequential结构),我们可以设计出来分支结构、循环结构、残差结构,这些都是可以用来提取更复杂的特征、解决更复杂的问题,当然这样的话训练需要的数据、算力、时间相应就会增加。关于神经网络的输入输出可以参考这篇博客:https://www.cnblogs.com/xiaozhi_5638/p/12591612.html
传统机器学习
看完深度学习解决该问题的流程,我们再来看一下如何使用传统机器学习来解决该问题。传统机器学习做不到‘端到端’的全自动处理,对于一个具体的任务需要拆分成几步去解决,第一步就是特征工程,(以图片分类任务为例)需要人为确定使用哪种特征以及特征提取方式,第二步才是对已有特征进行训练,得到一个特征分类模型。这里有两个问题,一是人为确定使用哪种特征,需要专业人士判断;而是知道要使用什么特征后,如何去提取?相比深度学习而言,传统机器学习可以总结为‘半自动’模式:
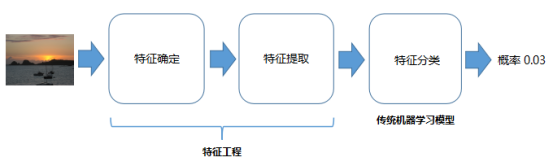
如上图所示,传统机器学习在解决当前具体问题时,需要人工确认使用什么特征,以及提取该特征的方法,最后才能用得到的特征去训练机器学习模型去做分类。那么这里有个比较重要:选择什么特征更有利于问题的解决呢?既要考虑特征对原数据的代表性,又要考虑特征提取的可行性。具体到当前图片二分类任务时,我们可以看到数据集中,绿植风景照大部分都是绿色,和其他图片在像素分布上有很大差异,因此我们可以选取‘颜色分布’来做为解决本次任务的图像特征,具体采用‘颜色直方图’的方式去生成每张图片的特征向量。
颜色直方图简单理解就是统计图片中每种颜色所占比例,RGB图片每个通道颜色值在0-255之间,如果我们将这个区间分成10等份(子区间)然后计算每个子区间颜色占比(和为1),那么就可以得到3个10维向量,将这3个向量合并组成一个30维的向量,那么这个30维向量就是基于颜色分布的图像特征。由于这种方式提取到的特征没有考虑颜色在图片中的位置分布,因此通常做法是,先将一张图切成若干等份,然后分别计算单个图片区域的特征向量,最后将所有图片区域的特征向量拼接起来得到最终的图像特征。如果将图片切成5份,那么最终得到的特征向量维度为:5*3*10=150,这个特征向量从一定程度上代表了颜色位置分布。

如上图所示,利用颜色直方图可以为每张图片提取到一个150维的特征向量,后面我们再用这些特征向量训练机器学习模型,由于是一个二分类问题,我们直接选用‘逻辑回归’算法即可。需要明确的是,一些常见的图像特征点提取方法比如SIFT、SURF等等在这里是无效的,因为这些方式提取得到的特征向量更侧重描述原图像中像素之间的局部联系,很显然对于我们这个图片二分类任务而言,根据颜色分布提取到的特征更适合解决本问题。这也同时说明,在传统机器学习中的特征提取环节非常重要,特征工程也是制约传统机器学习发展的一大瓶颈。
现在总结一下
深度学习在解决问题的时候采用‘端到端’的全自动模式,中间无需人为干预,能够自动从原有数据中提取到有利于解决问题的特征,该部分原理相对来讲‘可解释性弱’。同时,神经网络的结构多变,可以根据问题的复杂程度灵活调整网络结构,更复杂的网络结构需要更多更丰富的训练数据去拟合参数,相对应对算力的要求也高一些。而对于传统机器学习来讲,一个很重要的工作就是特征工程,我们必须人工筛选(挑选)什么特征有利于问题的解决,比如本篇文章中的例子,像素分布就是一个很好的特征,同时我们还需要人工去提取这些特征,这部分原理相对来讲‘可解释性更强’。对于特征工程这块工作而言,它对人工专业性要求较高,因为对于稍微复杂的问题,很难识别出数据集的哪些特征有利于解决问题,尤其像图片、语音、文本等等非结构化数据,这个也是制约传统机器学习发展的瓶颈之一。不管怎样,其实深度学习和传统机器学习解决问题的思路基本是一致的,我们可以看到本文中两种解决问题的过程中都会生成一个特征向量,一个256维,一个150维,最后根据特征向量分类。有问题的朋友欢迎留言讨论。