与多目标跟踪(Multiple Object Tracking简称MOT)对应的是单目标跟踪(Single Object Tracking简称SOT),按照字面意思来理解,前者是对连续视频画面中多个目标进行跟踪,后者是对连续视频画面中单个目标进行跟踪。由于大部分应用场景都涉及到多个目标的跟踪,因此多目标跟踪也是目前大家主要研究内容,本文也主要介绍多目标跟踪。跟踪的本质是关联视频前后帧中的同一物体(目标),并赋予唯一TrackID。

随着深度学习的兴起,目标检测的准确性越来越高,常见的yolo系列从V1到现在的V8,mAP一个比一个高,因此基于深度学习的目标检测算法实际工程落地也越来越广泛,基于目标检测的跟踪我们称为Tracking By Detecting,目标检测算法的输出就是这种跟踪算法的输入,比如left, top,width,right坐标值。这种Tracking By Detecting的跟踪算法是大家讲得比较多、工业界用得也比较广的跟踪算法,我觉得主要还是归功于目标检测的成熟度越来越高。下面这张图描述了Tracking By Detecting的跟踪算法流程:
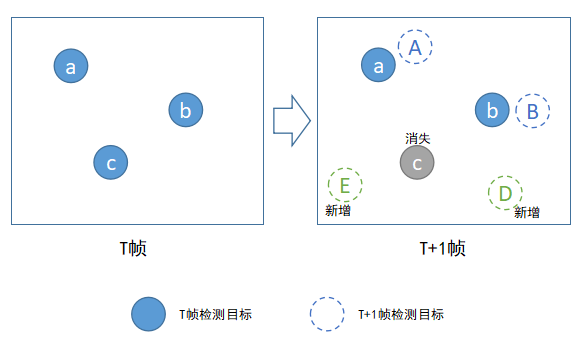
由上图可以看出,这种跟踪算法要求有一种检测算法配合起来使用,可想而知,前面检测算法的稳定性会严重影响后面跟踪算法的效果。图中实线圆形代表上一帧检测到的目标,虚线圆形代表当前帧检测到的目标,如何将前后帧目标正确关联起来就是这类跟踪算法需要解决的问题。目标跟踪是目标检测的后续补充,它是某些视频结构化应用中的必备环节,比如一些行为分析的应用系统中都需要先对检测出来的目标进行跟踪,然后再对跟踪到的轨迹进行分析。

目标关联
文章开头提到过,目标跟踪的本质是关联视频前后帧中的同一物体(目标),第T帧中有M个检测目标,第T+1帧中有N个检测目标,将前一帧中M个目标和后一帧中N个目标一一关联起来,并赋予唯一标识TrackID,这个过程就是Tracking By Detecting跟踪算法的宏观流程。
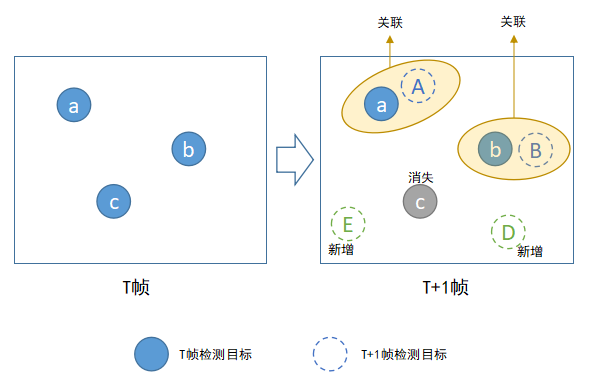
上图描述目标关联的具体流程,在实际目标关联过程中,我们需要考虑的有:
- 如何处理中途出现的新目标
- 如何处理中途消失的目标
- 正确目标关联
理想情况下,同一个物体(目标)在视频画面中从出现到消失,跟踪算法应该能赋予它唯一一个标识(TrackID),不管目标是否被遮挡、目标是否发生严重形变、是否和其他目标相距太近(相互干扰),只要这个目标被正确检测出来,跟踪算法都应该能够正确关联上。但实际上,物体遮挡是跟踪算法最难解决的难题之一,物体被频繁遮挡是TrackID变化的主要原因。原因很简单,物体被遮挡后(或其他原因),检测算法检测不到,跟踪算法无法连续关联到每帧的数据,等该物体再出现时,物体在画面中的位置、物体的外观形状与消失之前相比都发生了很大变化,而跟踪算法恰恰主要是根据物体的位置、外观来进行数据关联的。下面主要介绍目标跟踪中两种方式,一种容易实现、速度快,算法纯粹基于目标在画面中的位置来进行数据关联;另一种相对复杂,速度慢,算法需要提取前后帧中每个目标的图像特征(features),然后根据特征匹配去做数据关联。
基于坐标的目标关联
基于坐标(目标中心点+长宽)的目标关联是相对简单的一种目标跟踪方式,算法认为前后帧中挨得近的物体为同一个目标,因为物体移动是平滑缓慢的,具体可以通过IOU(交并比,前后两帧中目标检测方框的重叠程度)来计算,这种算法速度快、实现容易,在前面检测算法相对稳定的前提下,这种跟踪方式能够取得还不错的效果,由于速度快,这种方式一般可以用于对实时性(realtime)要求比较高的场合。缺点也很明显,因为它仅仅是以目标的坐标(检测算法的输出)为依据进行跟踪的,所以受检测算法影响非常大,如果检测算法不稳定,对于一个视频帧序列中的目标,检测算法经常漏检,那么通过这种方式去跟踪效果就非常差。另外如果场景比较复杂,目标比较密集,这种跟踪方式的效果也比不会太好,因为目标密集,相邻目标的坐标(left、top、width、height)重合度比较高,这给基于坐标的目标关联带来困难。
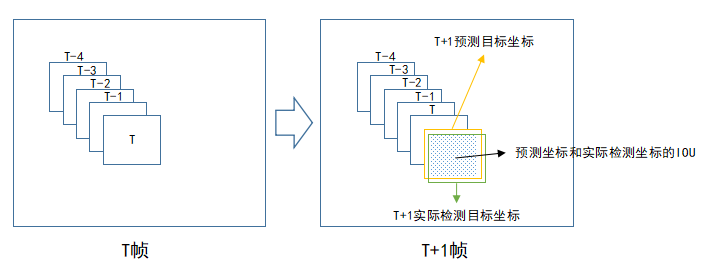
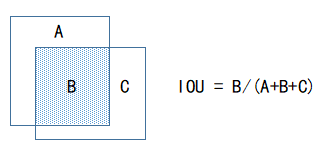
如上图,在T+1帧中,我们根据目标前面若干帧的坐标预测它在本帧中的坐标(预测坐标),然后再将该预测坐标与本帧实际检测的目标坐标进行数据关联。之所以需要先进行预测再关联,是因为为了减少关联过程的误差,常见预测算法可以使用卡尔曼滤波,根据目标前面若干坐标值预测下一坐标值,并且不断地进行自我修正,卡尔曼滤波算法网上有开源代码。IOU(交并比)是衡量两个矩形方框的重叠程度,IOU值越大代表矩形框重叠面积越大,它是目标检测中常见的概念。在这里,我们认为IOU越大,两个目标为同一物体的可能性越大。
基于特征的目标关联
纯粹基于坐标的目标跟踪算法有一定的局限性,单靠目标坐标去关联前后帧的同一目标在有些场合下效果比较差。在此基础上,有人提出结合目标外观特征匹配做目标关联,换句话说,在做目标关联的时候,除了依赖目标坐标外,还考虑目标的外观特征,道理很简单:
“前后两帧中挨得近的物体且外观长得比较像的物体为同一目标。”
这样的跟踪方式准确率更高,但是同时出现了一个问题:如何判断两个物体外观长得像?在计算机视觉中,有一个专门的研究领域叫Target Re-Identification(目标重识别),先通过对两个待比较目标进行特征编码(特征提取),然后再根据两个特征的相似度,来判断这两个目标是否为同一个物体,两个特征越相似代表两个目标为同一个物体的可能性越大。Target Re-Identification常用在图像搜索、轨迹生成(跨摄像机目标重识别)以及今天这里要说的目标跟踪。
熟悉深度学习的童鞋应该很清楚,神经网络的主要作用就是对原始输入数据进行特征编码,尤其在计算机视觉中,卷积神经网络主要用于图像的特征提取(Feature Extraction),从二维图像中提取高维特征,这些特征是对原始输入图像的一种抽象表示,因此训练神经网络的过程也可以称为Representation Learning。相同或者相似的输入图片,神经网络提取到的特征应该也是相同或者相似的。我们只要计算两个特征的相似度,就可以判断原始输入图像的相似性。
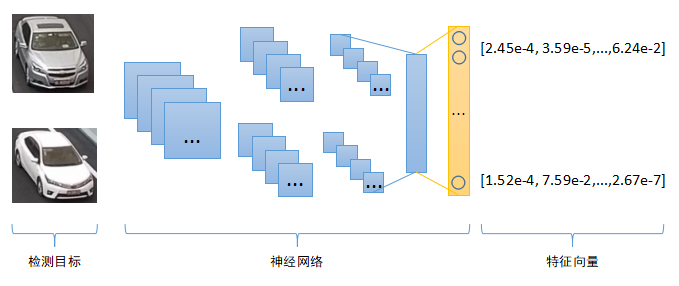
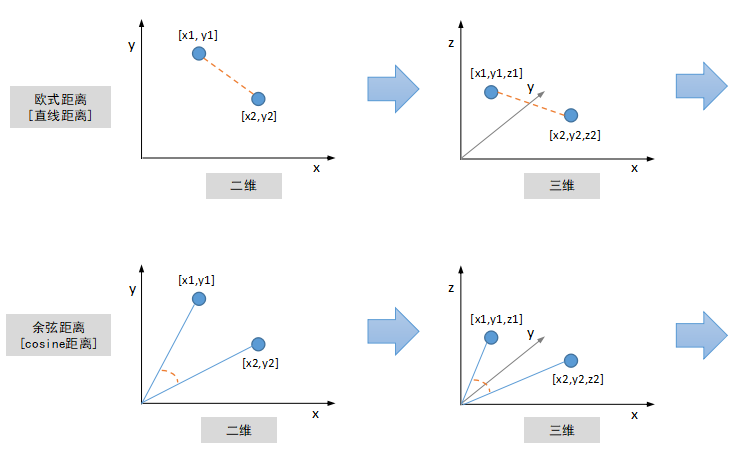
那么如何计算两个图像特征的相似度呢?图像特征的数学表示是一串数字,组合起来就是一个Vector向量,二维向量可以看成是平面坐标系中的点,三维向量可以看成立体空间中的点,依次类推,因此图像特征也被称作为“特征向量”。有很多度量标准来衡量两个特征向量的相似程度,最常见的是“欧式距离”,即计算两点之间的直线距离,二维三维空间中两点之间的直线距离我们都非常熟悉,更高维空间中两点距离计算原理跟二三维空间保持一致。另外除了“欧式距离”之外,还有一种常见距离度量标准叫“余弦距离”,计算两个向量(点到中心原点的射线)之间的夹角,夹角越小,代表两个向量越相似。
外观特征提取是一个耗时过程,因此对实时性要求比较高或者需要同时处理视频路数比较多的场合可能不太适合。但是这种基于外观特征的跟踪方式效果相对更好,对遮挡、目标密集等问题鲁棒性更好,因为目标遮挡再出现后,只要特征提取网络训练得够好,目标尺寸、角度变化对它的外观特征影响不大,因此关联准确性也更高。类似的,这个也适用于目标密集场景。外观特征提取需要定义一个合适的神经网络结构,采用相关素材去训练这个网络,网上有很多公开的Person-ReId数据集可以用来训练行人跟踪的特征提取网络,类似的,还有一些Vehicle-ReId数据集可以用来训练车辆跟踪的特征提取网络,关于这块的内容,也是一个值得深入研究的领域,由于本篇文章主要介绍目标跟踪,所以暂不展开讲述了。

本文开头第一张图是基于坐标的跟踪方式效果图,上图是基于外观特征的跟踪方式效果图,我们可以看到,第一张图中目标被遮挡再出现后,目标ID发生了变化,而第二张图中大部分时候目标ID都比较稳定,同样,人群密集场合中,同一目标ID发生改变的几率也小。实际上,同一目标ID是否发生变化是衡量跟踪算法好坏的一个重要指标,叫IDSwitch,同一目标ID变化次数越少,可以一定程度代表算法跟踪效果越好。
参考论文
| 1 | Simple Online Real-time Tracking | https://arxiv.org/pdf/1602.00763.pdf |
| 2 | Simple Online Real-time Tracking with a deep association metric | https://arxiv.org/pdf/1703.07402.pdf |
| 3 | Multiple Object Tracking: A Literature Review | https://arxiv.org/pdf/1409.7618.pdf |