最简单的X->Y映射
读书时代课本上的函数其实就是我们最早接触关于“映射”的概念,f(x)以“某种逻辑”将横坐标轴上的值映射到纵坐标轴。后来学习编程之后接触了函数(或者叫方法)的概念,它以“某种逻辑”将函数输入映射成输出,映射逻辑就是函数本身的实现过程。映射就是将若干输入以某种逻辑转换成若干输出,课本上的函数是这样,编程中的函数是这样,深度学习中神经网络同样是这样。
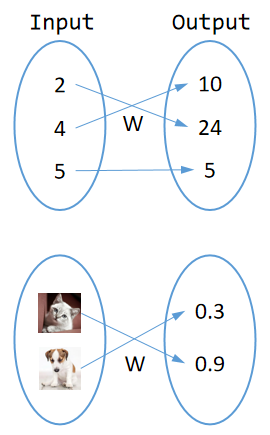
最简单的映射逻辑是线性映射,类似f(x)=w*x + b这样,它的函数图像是一条直线,其中w和b是映射过程用到的参数。高中数学中的抛物线f(x)=a*x*x + b*x +c 是一种比线性映射更复杂的映射关系,同样a、b、c是该映射过程要用到的参数。 这里不管是w还是abc这样的参数,同样存在于神经网络这种高复杂度的映射过程之中,事实上,我们完全可以将神经网络类比为我们更为熟悉的直线、抛物线结构。
与我们读书学习直线、抛物线不同的是,书本中直线、抛物线函数的参数大部分时候都是已知的,而神经网络中的参数是未知的,或者说不是最优的,我们需要使用已知的样本(输入/输出)去拟合网络,从而得出最优的参数值,然后将拟合(学习)到的参数应用到新数据中(只有输入),拟合的这个过程叫做“训练模型”或者“学习”。
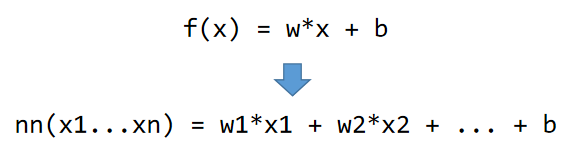
神经网络的输入输出
前面说到映射过程有输入和输出,同样神经网络也有输入和输出。就计算机视觉领域相关任务来讲,有图像分类网络,有目标检测、分割等网络,也有专门用于图像特征提取的网络,这些网络的输入基本都是图片,输出要么是分类概率值,要么是跟目标有关的像素坐标值,或者是高维特征向量值,这些输出有一个共同的特点,都属于数字类输出,就像我们刚接触机器学习时预测房价的案例,算法输出是房价,也是数字类型。那么神经网络是否还有更复杂的输出格式呢?答案是有,神经网络可以输出更高维的数据结构,比如图片。虽然严格来讲,图片也是由数字组成,但是为了与前面提到的简单输出类型区分,我们可以将输出图片的这类神经网络称为“生成型网络”。顾名思义,生成型网络的特点是可以生成类似图片这种直观结果(或者类似网络输入那种更高维数据)。
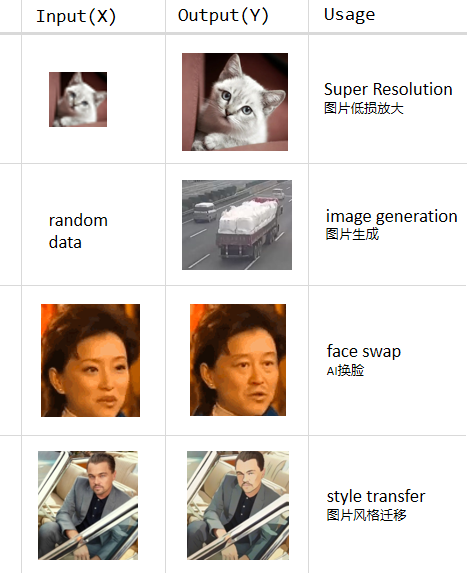
生成型网络的训练方式一般比较特别,大部分都是无监督学习,也就是事先无需对样本做人工标注。事实上,了解生成型网络是我们熟悉无监督学习的一种非常好的途径。
生成型网络的实现方式常见有两种,一个是AutoEncoder,翻译成中文叫“自编码器”,基本原理就是将输入图片先编码,生成一个特征表达,然后再基于该特征重新解码生成原来的输入图片,编码和解码是两个独立的环节,训练的时候合并、使用的时候拆开再交叉组合。前几年非常火的AI换脸就是基于AutoEncoder实现的,代码非常简单,之前的一篇文章对它有非常详细的介绍。另一个是GAN,全称Generative Adversarial Networks,翻译成中文是“生成对抗型网络”,它也是由两部分组成,一个负责生成一张图片,一个负责对图片进行分类(判断真假),训练的时候一起训练,使用的时候只用前面的生成网络。GAN也是本篇文章后面介绍的重点内容。
GAN生成对抗型网络工作原理
首先要明确地是,最原始的GAN是2014年提出来的,它可以基于一个无任何标注的图片样本集,生成类似风格的全新图片,就像一个画家,看了一些示例后,可以画出类似风格的画。2014年提出来的GAN结构相对简单,也存在一些缺陷,比如生成的图片分辨率太低、网络训练很难收敛。后面有人陆陆续续提出了各种改进版本的GAN(变种),虽然各方面都有所调整,但是整体思想仍然沿用第一版,这里也是介绍最原始GAN网络的工作原理。
GAN网络主要由两子网络组成,一个学名叫Generative Network(顾名思义,生成网络),输入随机数,输出一张固定尺寸的图片(比如64*64大小),另一个学名叫Discriminative Network(顾名思义,辨别网络),输入前一个网络生成的图片以及训练样本集中的图片,输出真和假(生成的为假、样本集中的为真)。如果单独分开来看,这两没什么特别的,一个负责生成图片、一个负责判别真假。但是,GAN高妙之处就在于这两在训练过程中并不是独立的。我们先来看下GAN的结构:
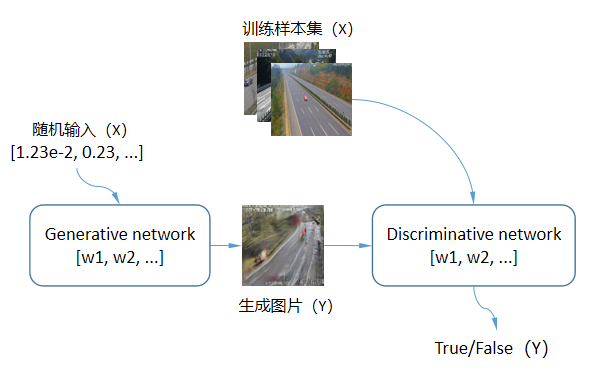
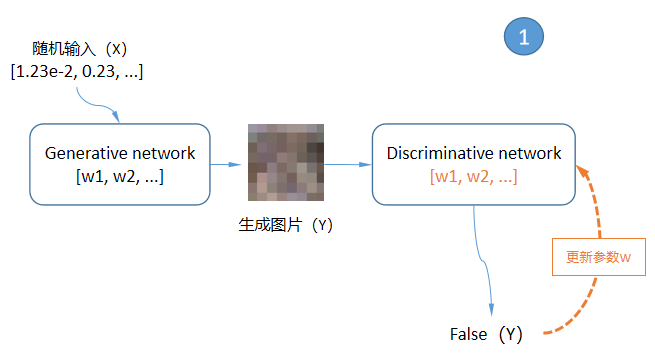
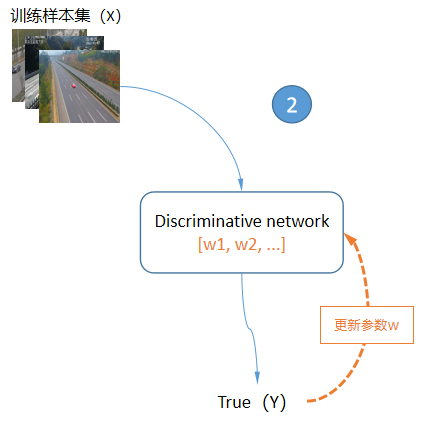
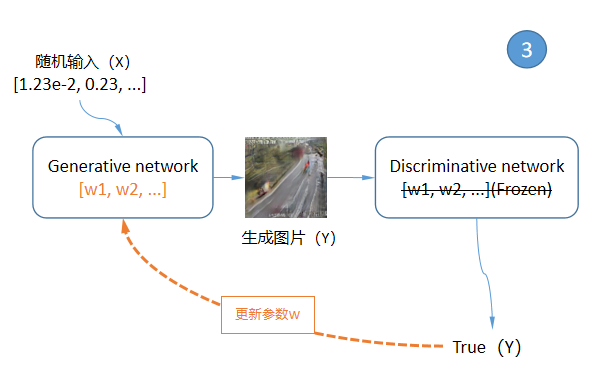
上面显示的GAN网络结构其实非常简单,但是只看这张图的人可能会有一个疑问?训练样本集只作为辨别网络(Discriminative network,简称D)的输入并参与训练,它是怎样对生成网络(Generative network,简称G)起到作用的?答案在GAN的训练过程中,GAN的训练方式主要可以归纳成3个要点:
1、将G的输出作为D的输入,并以False标签来训练D网络,更新D网络的参数,让D知道什么是假的;
2、将训练样本集输入D,并以True标签来训练D网络,更新D网络的参数,让D知道什么是真的;
3、将D的参数冻结,再将D和G两个网络串起来,G的输出还是作为D的输入,但是这次以True标签来训练整个组合网络。由于D的参数已经冻结,所以整个训练过程只会更新前面G网络的参数,让G知道如何生成看起来像“真的”图片。
上面的过程1和过程2让D越来越聪明,知道什么是真的、什么是假的。过程3让G也越来越聪明,知道如何调整自己的参数,才能让生成的图片更能欺骗D。随着上面的过程不断反复,G不断的更新自己的参数,虽然输入的一直是随机数,但是输出的图片却越来越像训练样本集中的图片,到此完成了对G的训练。下面用图来说明上面的过程:
GAN(变种网络)可以解决哪些任务?
基于GAN思想的生成型网络有很多应用,比如素材生成,当你已经有一定数量的图片样本后,你可以利用GAN生成更多类似但完全不同的图片,提升样本库的丰富性。目前比较成熟的风格迁移(style transfer)也用到了GAN思想,可以将一张手机拍摄的自然风景图片转换成山水画、卡通画风格。下面是利用Pro-GAN网络生成的图公路像素材,刚开始生成的图像模糊,随着训练时间增加,生成的图像越来越清晰、并且能够保持与已有样本集一致的风格。

